Introduction
Software teams are expected to move fast, release often, and still keep systems stable. That is not easy. Every release, infrastructure change, traffic spike, dependency issue, or monitoring gap can create risk in production. When a service slows down or goes offline, users do not care which team owns the problem. They only remember that the service failed.
That is why reliability has become a serious business and engineering priority.
In many organizations, development and operations used to be treated as separate worlds. One team built the product, and another team kept it running. But modern systems do not work well with that old model. Today, applications run across cloud platforms, containers, APIs, CI/CD pipelines, observability stacks, and distributed services. Because of that, reliability must be built into the engineering process itself.
This is where Site Reliability Engineering becomes valuable.
Site Reliability Engineering, or SRE, gives teams a better way to operate software systems. It combines software engineering thinking with operational responsibility. It helps teams define reliability goals, improve observability, reduce manual work, manage incidents well, and create stable systems without slowing innovation too much.
For engineers, SRE builds strong production thinking.
For managers, SRE creates a better framework for discussing uptime, service quality, support readiness, and operational maturity.
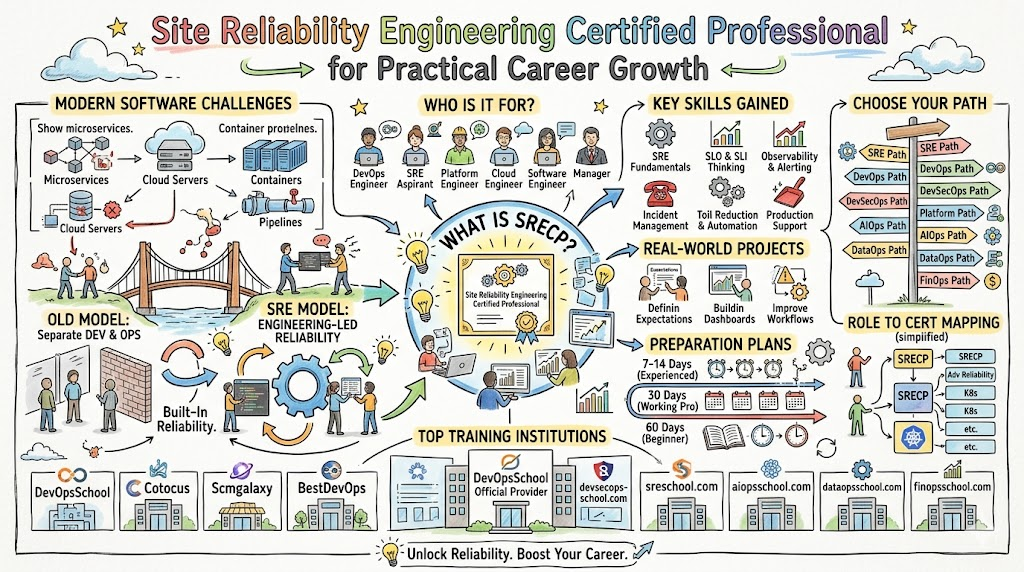
The Site Reliability Engineering Certified Professional, or SRECP, is designed for professionals who want to learn this discipline in a structured and career-focused way. It is useful for working engineers, aspiring SREs, DevOps professionals, cloud engineers, platform teams, and even managers who want clearer knowledge of modern reliability practices.
This guide explains what SRECP is, why it matters, why certification is useful, who should take it, what skills it develops, how to prepare, and what path you can take after completing it.
What is Site Reliability Engineering Certified Professional (SRECP)?
Site Reliability Engineering Certified Professional is a certification focused on helping professionals understand how modern production systems are made reliable, scalable, observable, and easier to support.
In simple words, SRECP teaches you how to run important systems in a smarter way.
This certification is not only about monitoring dashboards or reacting to alerts. It is about learning how reliability works as a complete discipline. That includes service expectations, operational automation, incident handling, observability, platform health, and long-term improvement.
Why it Matters in Today’s Software, Cloud, and Automation Ecosystem
Modern software is fast, distributed, and highly connected. Teams now work with microservices, cloud-native platforms, containers, CI/CD pipelines, infrastructure as code, telemetry tools, and multiple production environments. This gives organizations speed and scale, but it also increases complexity.
When complexity increases, reliability becomes harder.
A single deployment mistake can affect many users. A noisy alerting setup can hide serious issues. Weak observability can delay incident response. Manual work can slow recovery. Without proper service goals, teams may not even know whether reliability is improving or declining.
This is why Site Reliability Engineering matters so much.
Why Certifications are Important for Engineers and Managers
Real project experience is always important, but experience alone can be uneven. Many professionals become strong in one tool or one area of operations while remaining weak in others. Someone may know monitoring tools well but not understand service-level thinking. Another person may know infrastructure deeply but not know how to reduce toil. Someone else may be good at incident response but weak at prevention.
A certification helps organize learning.
It gives professionals a structured path so they can understand the key ideas, the relationships between those ideas, and the practical meaning behind them. Instead of learning random concepts in isolation, they learn a connected model.
For engineers, certification helps in several ways.
It improves focus. It shows what to study and what matters most.
It builds confidence. Many professionals already do part of the work, but certification helps them see the bigger picture.
It improves career positioning. It becomes easier to show employers that your knowledge is structured and relevant to modern roles.
For managers, certification has another value.
Managers need shared language. They need frameworks to understand service quality, operational risk, team readiness, escalation maturity, and support load. Certification helps them guide teams more effectively because it gives them a clearer understanding of how reliability should be approached.
A certificate alone does not create mastery. Practical ownership still matters most. But certification can make that practical learning more intentional, more complete, and more visible.
Why Choose DevOpsSchool?
DevOpsSchool is a strong choice because it is well aligned with the needs of working professionals. Learners looking at SRECP are usually engineers, leads, operations professionals, platform teams, or managers who want training that feels relevant to actual production environments. They do not want abstract explanations alone. They want useful understanding.
Another reason DevOpsSchool stands out is that it fits a broad but connected audience. SRECP is helpful not only for dedicated SRE aspirants but also for DevOps engineers, cloud teams, platform engineers, and technical managers. That makes the program more useful in the real world where responsibilities often overlap.
For professionals who want practical learning with direct career relevance, DevOpsSchool is a sensible option.
Certification Deep-Dive: Site Reliability Engineering Certified Professional (SRECP)
What is this certification?
SRECP is a professional certification built around the principles and practices of Site Reliability Engineering. It helps learners understand how stable systems are designed, operated, measured, and improved in real production settings.
This certification is not about memorizing definitions.
It is about understanding how engineering teams improve service reliability through better observability, smarter automation, clearer service expectations, stronger incident discipline, and continuous operational improvement.
Who should take this certification?
This certification is a strong fit for:
- DevOps engineers who want deeper reliability knowledge
- SRE aspirants who want a clear learning path
- Platform engineers responsible for shared services
- Cloud engineers managing uptime and performance
- Operations professionals moving toward automation-first work
- Engineering managers who oversee service quality and operations
- Software engineers who work close to production systems
If your role touches deployment quality, uptime, monitoring, platform health, or incident readiness, this certification can be useful.
Certification Overview Table
| Certification Name | Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
|---|---|---|---|---|---|---|
| Site Reliability Engineering Certified Professional (SRECP) | SRE | Professional | DevOps engineers, SRE aspirants, platform engineers, cloud engineers, operations professionals, engineering managers | Basic understanding of Linux, cloud, CI/CD, monitoring, and production support is helpful | Reliability engineering, observability, incident management, service-level thinking, automation, operational maturity, platform stability | Strong first step for the SRE path |
Site Reliability Engineering Certified Professional (SRECP)
What it is
SRECP is a role-focused certification for professionals who want to learn how reliability is managed in modern software environments. It helps turn general operations knowledge into a more complete and engineering-led reliability approach.
Who should take it
- DevOps engineers
- SRE aspirants
- Platform engineers
- Cloud engineers
- Operations professionals
- System administrators
- Technical leads
- Engineering managers
- Software engineers working near production systems
Skills you’ll gain
- Strong understanding of SRE fundamentals
- Clear thinking around service quality and service expectations
- Better understanding of service-level concepts
- Stronger observability awareness
- Better alerting judgment
- Improved incident-response thinking
- Stronger automation-first mindset
- Better understanding of toil and how to reduce it
- Stronger production-support discipline
- Better connection between engineering work and business outcomes
Real-world projects you should be able to do after it
- Define reliability expectations for a service
- Build dashboards for service-health review
- Improve alerts so teams focus on useful signals
- Create a simple incident-management workflow
- Identify repetitive manual tasks and automation opportunities
- Improve deployment readiness with reliability thinking
- Contribute to better visibility across production systems
- Help teams discuss service quality in measurable terms
- Support long-term reliability improvements
- Contribute to platform-stability initiatives
Preparation plan
7–14 days
This is best for experienced professionals. If you already work in DevOps, cloud, operations, or platform roles, use this period for focused revision. Review core SRE concepts, service-level thinking, incident flow, observability basics, and automation practices.
30 days
This is the best plan for most working professionals. Spend the first part understanding concepts clearly. Use the second part to relate those concepts to real production scenarios. Use the final part for revision, short notes, and practical review.
60 days
This is ideal for beginners or career changers. Start with Linux basics, cloud fundamentals, monitoring, CI/CD, containers, and operations basics. Then move into SRE concepts, reliability goals, incident handling, observability, and automation. Finish with review and small practical exercises.
Common mistakes
- Thinking SRE is only about monitoring
- Learning tools without understanding the ideas behind them
- Ignoring service-level thinking
- Focusing only on incidents, not prevention
- Treating automation as optional
- Studying theory without practical examples
- Forgetting the business impact of reliability
- Preparing without connecting concepts to real systems
Best next certification after this
A good next step depends on your direction.
If you want to stay close to reliability, go for an observability-focused certification.
If you want stronger infrastructure depth, choose a Kubernetes-related certification.
If you want broader ownership and leadership, move toward a DevOps or management-focused certification.
Choose your path
DevOps path
This path is ideal for professionals focused on CI/CD, automation, infrastructure, and release systems. SRECP adds reliability depth and helps DevOps professionals move from delivery speed toward service quality and production maturity.
DevSecOps path
This path fits professionals working at the intersection of security and delivery. SRECP adds resilience, operational discipline, and better incident thinking, which strengthens secure engineering environments.
SRE path
This is the most direct route for professionals who want to specialize in uptime, observability, incident response, and reliability improvement. SRECP is a strong foundation for this track.
AIOps/MLOps path
This path is useful for professionals working with intelligent automation or machine learning systems. These environments still need service stability, observability, and disciplined operations. SRECP provides that reliability base.
DataOps path
Data systems also need stable pipelines, predictable workflows, and operational visibility. SRECP helps DataOps professionals add stronger service thinking to data platforms and analytics environments.
FinOps path
FinOps focuses on cost efficiency and cloud governance. Reliability supports this because unstable systems often create waste, repeated recovery work, and poor resource usage. SRECP can complement FinOps very well.
Role → Recommended certifications mapping
| Role | Recommended certifications |
|---|---|
| DevOps Engineer | SRECP, DevOps-focused certifications, Kubernetes-related certifications |
| SRE | SRECP first, then observability and advanced reliability certifications |
| Platform Engineer | SRECP plus Kubernetes, Terraform, and platform-engineering learning |
| Cloud Engineer | SRECP plus cloud operations or architecture certifications |
| Security Engineer | DevSecOps certifications first, then SRECP for resilience depth |
| Data Engineer | DataOps learning plus SRECP for operational reliability |
| FinOps Practitioner | FinOps learning plus SRECP for efficiency and stability alignment |
| Engineering Manager | SRECP plus leadership-focused DevOps, SRE, or platform strategy certifications |
Next certifications to take
Same track
An observability-focused certification is a very good next step after SRECP. Once you understand reliability concepts, deeper knowledge of logs, metrics, traces, dashboards, and telemetry becomes very useful.
Cross-track
A Kubernetes-related certification is a strong cross-track option. Many modern workloads run in containerized environments, so Kubernetes knowledge makes reliability work more practical.
Leadership
A DevOps or engineering-management certification is a good leadership move. It suits professionals who want to move from individual contribution into operational governance, team leadership, or platform ownership.
List of top institutions which provide help in Training cum Certifications for Site Reliability Engineering Certified Professional (SRECP)
DevOpsSchool
DevOpsSchool is the direct provider of the SRECP certification, so it is the most aligned choice for learners who want official guidance and structured preparation. It is suitable for both engineers and managers who want practical reliability training.
Cotocus
Cotocus can be helpful for professionals looking for technical support and implementation-focused learning. It may support learners who want more practical understanding of cloud, automation, and engineering workflows connected to reliability.
Scmgalaxy
Scmgalaxy is known for technical education around DevOps, automation, and engineering tools. It can help learners strengthen their core technical foundation before moving deeper into specialized SRE topics.
BestDevOps
BestDevOps is often recognized in the broader DevOps and cloud learning space. It can support structured learning across infrastructure, automation, and engineering practices that connect well with reliability careers.
devsecopsschool.com
This platform is useful for professionals who want to combine reliability thinking with secure delivery practices. It is especially relevant where resilience and security both matter.
sreschool.com
SRESchool is naturally relevant for learners who want deeper focus on reliability engineering. It can support growth in observability, incidents, service health, and operational maturity.
aiopsschool.com
AIOpsSchool can be useful for professionals interested in intelligent automation and analytics-driven operations. It is a strong complementary path for advanced operations learning.
dataopsschool.com
DataOpsSchool is helpful for professionals working on data platforms, pipelines, and analytics operations. It supports reliability-focused thinking in data-heavy environments.
finopsschool.com
FinOpsSchool is relevant for professionals focused on cloud cost governance, optimization, and efficiency. Since stable systems often support better financial outcomes, it can complement SRE learning well.
FAQs
1. Is SRECP a beginner-level certification?
It is better described as a professional-level certification. Beginners can still pursue it, but they usually need a longer preparation plan.
2. How difficult is the SRECP certification?
The difficulty is moderate to high depending on your background. Professionals already working in cloud, DevOps, platform, or operations roles usually find it more manageable.
3. How much preparation time is enough?
For many working professionals, 30 days is a practical target. Experienced engineers may need less. Beginners may need closer to 60 days.
4. Do I need prior operations experience?
It helps, but it is not mandatory. DevOps, cloud engineering, backend development, platform work, and system administration can all support SRE learning.
5. Is SRECP useful for software engineers?
Yes. Software engineers working near backend systems, APIs, cloud services, or production environments can benefit a lot from it.
6. Is it only for people with the SRE title?
No. It is useful across DevOps, platform engineering, cloud operations, support engineering, and management roles.
7. Will it help with career growth?
Yes. It can strengthen your profile for reliability-focused roles and improve readiness for production ownership.
8. Is this certification useful for managers?
Yes. Managers benefit because it helps them understand service quality, incidents, uptime, and operational maturity in a more structured way.
9. What should I study before starting?
Linux basics, cloud concepts, monitoring, containers, CI/CD, and production-support fundamentals are all useful topics.
10. Is SRECP only about monitoring and alerts?
No. Monitoring is only one part. The certification also covers service quality, service-level thinking, automation, incident discipline, and operational improvement.
11. Should I take Kubernetes certification before SRECP?
That depends on your role. If your work is more reliability-focused, SRECP is a strong first step. If your environment is heavily Kubernetes-based, both paths can complement each other.
12. Will SRECP help in real-world projects?
Yes. Its value becomes much stronger when you apply it to dashboards, alerting, incident flow, automation, and service-improvement efforts in production.
FAQs on Site Reliability Engineering Certified Professional (SRECP)
1. What does SRECP stand for?
It stands for Site Reliability Engineering Certified Professional.
2. What is the main purpose of this certification?
Its main purpose is to help professionals understand and apply reliability engineering practices in modern production environments.
3. Is SRECP a good option for DevOps engineers?
Yes. It is a strong next step for DevOps professionals who want deeper reliability and production maturity.
4. Can managers benefit from SRECP?
Yes. It helps managers make better decisions around service health, uptime, incidents, and operational readiness.
5. Is SRECP relevant in cloud-native environments?
Yes. Cloud-native systems are exactly where structured reliability practices become highly valuable.
6. What makes it different from general operations learning?
It focuses on engineering-led reliability rather than only reactive support and manual troubleshooting.
7. Is SRECP useful for platform engineers?
Yes. Platform engineers can use it to improve stability, observability, and production discipline across shared services.
8. What is the biggest value of SRECP?
Its biggest value is that it turns scattered operational experience into a clearer and more complete reliability mindset.
Conclusion
Site Reliability Engineering Certified Professional is a strong certification for professionals who want serious growth in modern reliability work. It does not stay limited to one tool, one platform, or one narrow support task. Instead, it helps learners understand how service quality, automation, observability, incident response, and system stability work together in real engineering environments. That makes it highly relevant for DevOps engineers, SRE aspirants, cloud professionals, platform teams, software engineers, and engineering managers. In a world where users expect software to be fast, dependable, and always available, reliability has become one of the most valuable capabilities a professional can build. SRECP offers a practical and structured path to develop that capability with confidence.
Leave a Reply